这段时间蠢徒弟在搞一个英文文章的分析课题,需要统计词频和进行情感分析,可没有现成软件或软件只能对中文统计分析,所以就用Python实现了一个可以实现此功能的脚本。
一、英文词频统计
解决思路:借助字典,遍历读取文章中的单词,并去除"the"之类的StopWord。
核心代码如下:WordCount.py
import os
excludes = {'the', 'and', 'to', 'of', 'i', 'a', 'in', 'that',
'is', 'my', 'with', 'not', 'his', 'but', 'for','me',
'he', 'be', 'as', 'him', 'was','from','has','by','on'}
def wordcount(filename):
with open(filename,encoding='utf-8') as f: # 打开文件
lines = f.readlines() # 按行读取
s = "" # 初始化为空字符
for line in lines:
s += line.rstrip() # 字符串连接
s = s.lower() # 将所有单词转换成小写
for ch in '`!@#~$%^&*()_+-=*/{}[];,./?<>': # 去掉所有的特殊符号
s = s.replace(ch, " ")
words = s.split() # split用空格分隔单词并变成列表返回
counts = {} # 建立一个字典
for word in words:
counts[word] = counts.get(word, 0) + 1
for word in excludes:
del (counts[word])
items = list(counts.items()) # 用list将counts变为一个列表类型
# counts.items()-->返回可遍历的(键,值)元组数组
items.sort(key=lambda x: x[1], reverse=True)
for i in range(20): # 输出词频排前20的单词
word, count = items[i]
print("{0:<15}{1:>5}".format(word, count))
if '__main__'==__name__:
import sys
if len(sys.argv)!=2:
print('python文件后需要加空格然后把待处理文件拖进来'.format(sys.argv[0]),file=sys.stderr)
sys.exit(0)
wordcount(sys.argv[1])使用方法:
创建"WordCount.py"文件备用,然后在命令行(win+R,cmd打开)中输入
python /路径/WordCount.py /txt文件路径这里的输入都可以通过拖动来完成,如下面动图: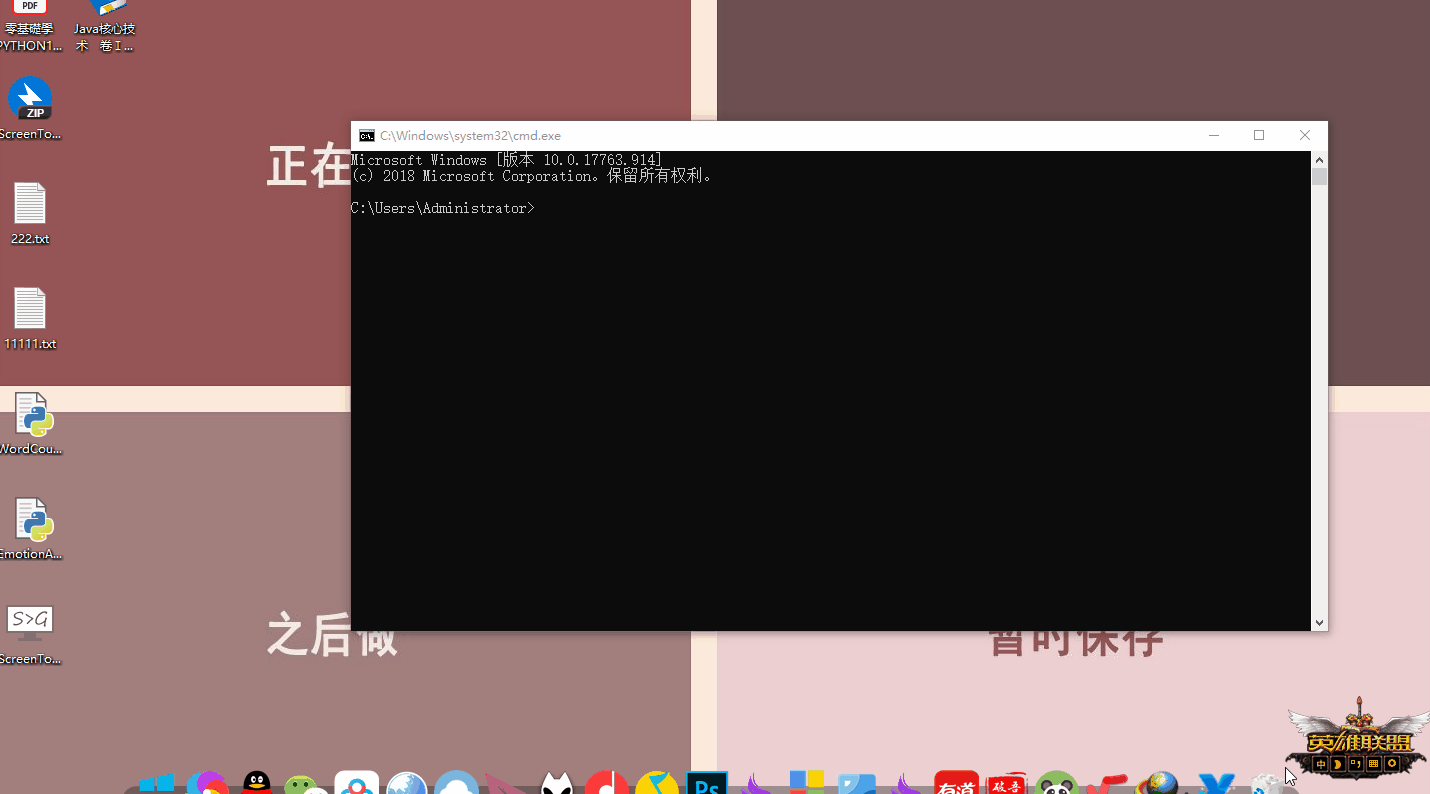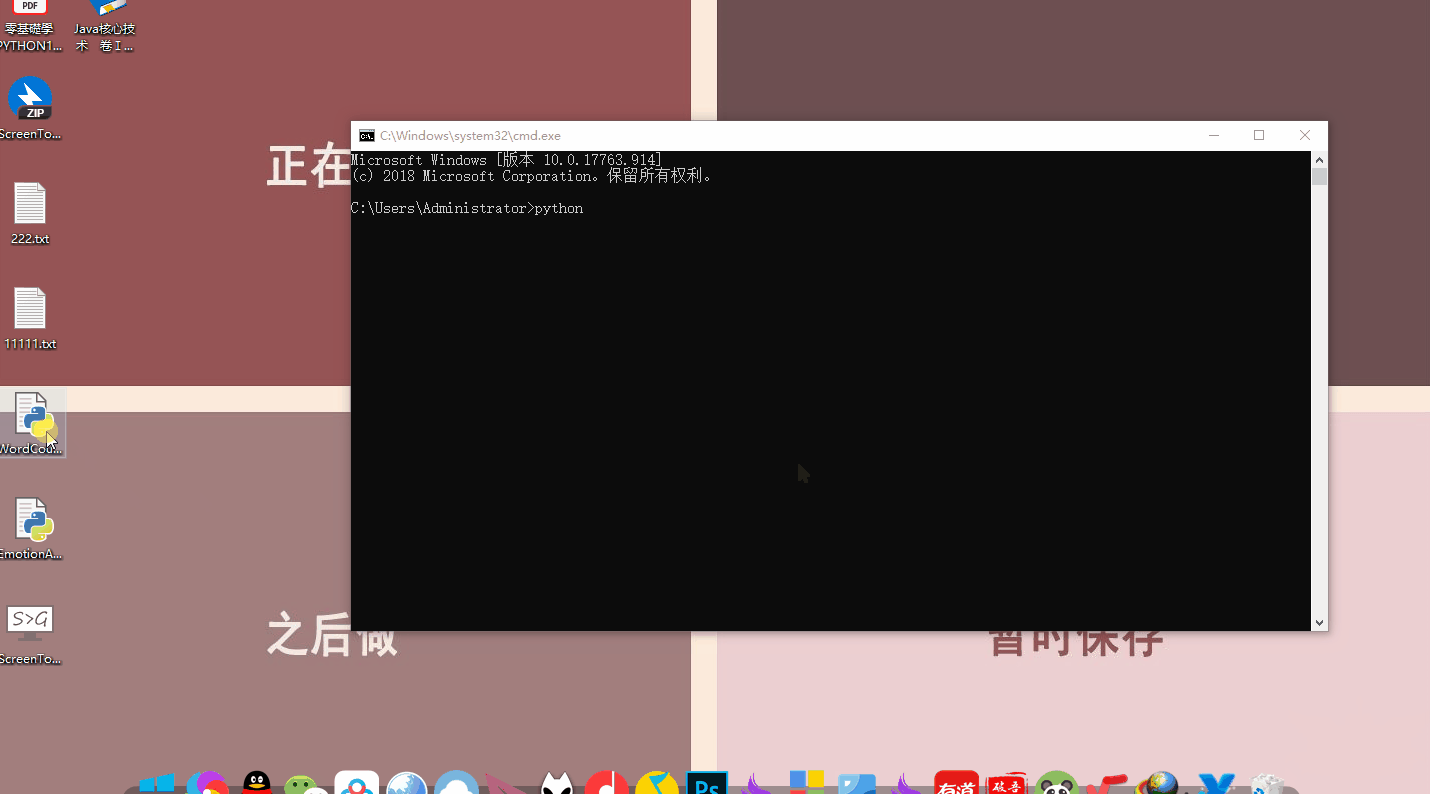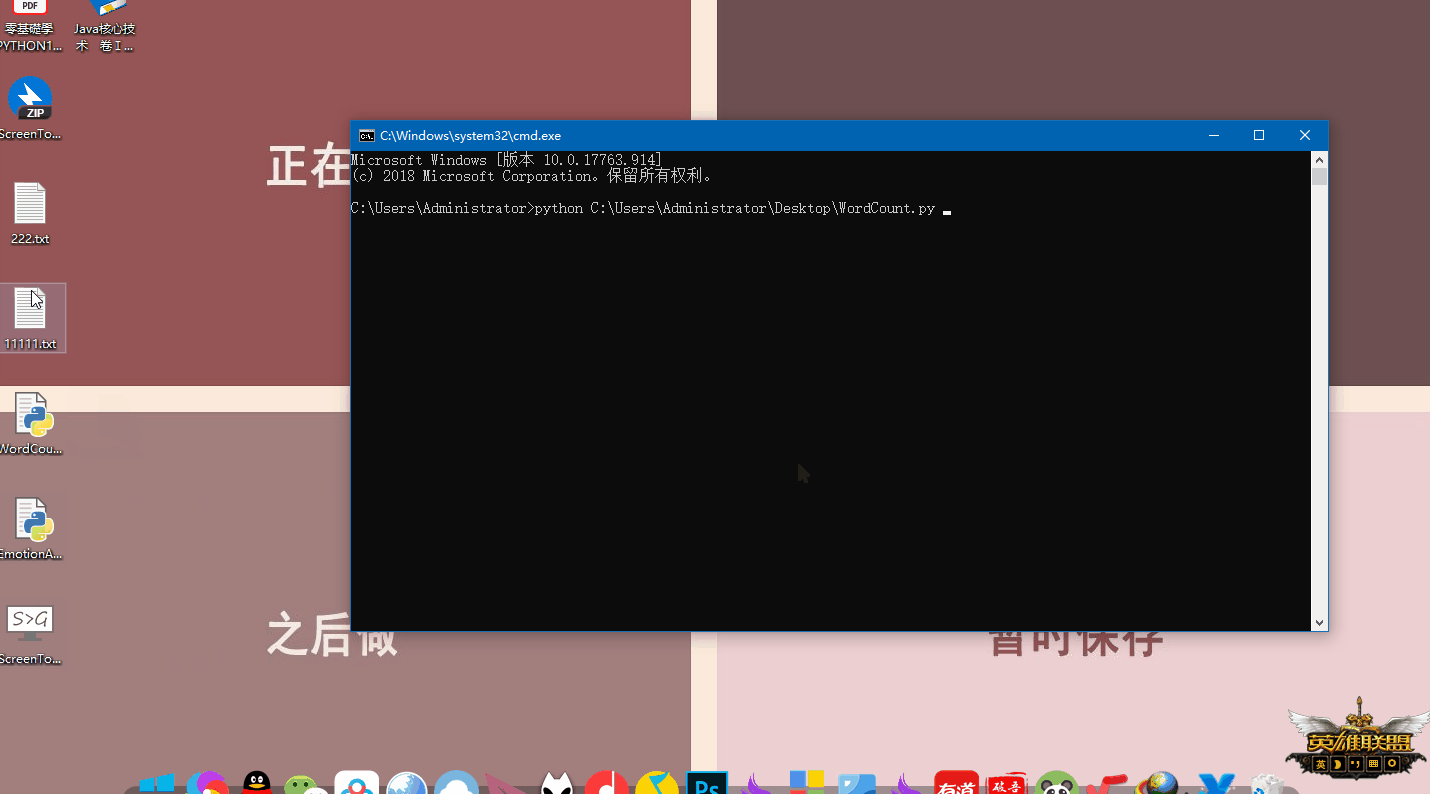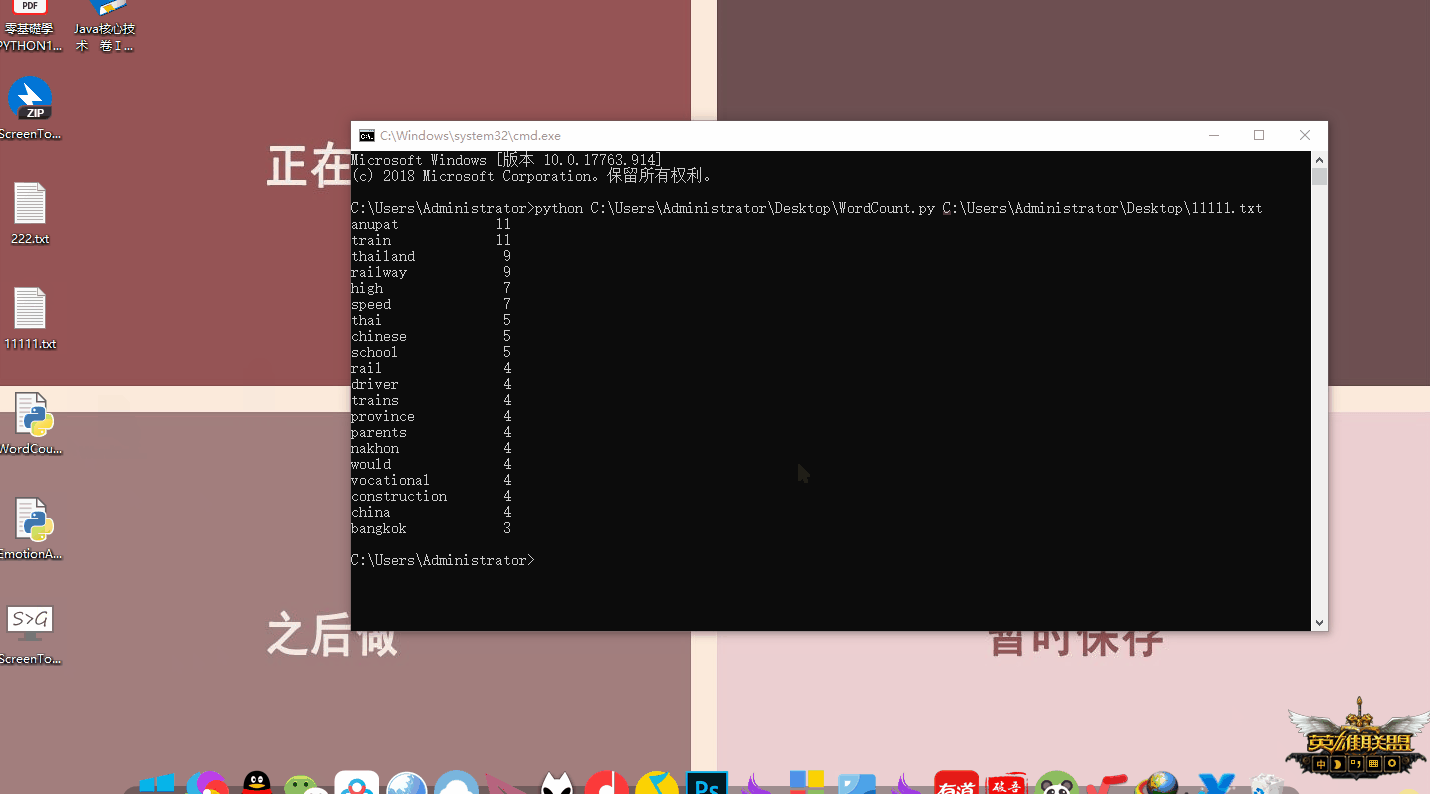
注意每次拖动前都要先加一个空格,不能让路径连在一起。
二、文本情感分析
文本情感分析(sentiment analysis)也称为意见挖掘,是指用自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息。
实现此功能用到的是NLTK,Natural Language Toolkit,自然语言处理工具包,在NLP领域中,是最常使用的一个Python库。NLTK由Steven Bird和Edward Loper在宾夕法尼亚大学计算机和信息科学系开发。
1、安装依赖包
对英文分析需要TextBlob,安装方法:
在命令行(win+R,cmd打开)中输入以下两行代码:
pip install textblob python -m textblob.download_corpora对中文分析需要SnowNLP,安装方法:
在命令行(win+R,cmd打开)中输入以下代码:
pip install snownlp2、调用实现核心代码
from textblob import TextBlob
import os
def emo_ana(filename):
with open(filename,encoding='utf-8') as f:
lines = f.readlines()
s = "" # 初始化为空字符
#v = "You are cute! I like you!"
for line in lines:
s += line.rstrip() # 字符串连接
blob = TextBlob(s)
# 拆分句子
# blob.sentences # [Sentence("I am happy today."), Sentence("I feel sad today.")]
# polarity代表情感极性,取值范围是[-1, 1],-1代表完全负面,1代表完全正面
# subjectivity代表主观性程度
#a = blob.sentences[0].sentiment # Sentiment(polarity=0.8, subjectivity=1.0)
#b = blob.sentences[1].sentiment # Sentiment(polarity=-0.5, subjectivity=1.0)
# 对整段话进行情感分析
c = blob.sentiment # Sentiment(polarity=0.15000000000000002, subjectivity=1.0)
print("全文情感分析结果如下:")
print(c)
print("(polarity代表情感极性,取值范围是[-1, 1],-1代表完全负面,1代表完全正面)")
print("(subjectivity代表主观性程度)")
if '__main__'==__name__:
import sys
if len(sys.argv)!=2:
print('python文件后需要加空格然后把待处理文件拖进来'.format(sys.argv[0]),file=sys.stderr)
sys.exit(0)
emo_ana(sys.argv[1])3、使用方法
创建"EmotionAna.py"文件备用,然后在命令行(win+R,cmd打开)中输入
python /路径/EmotionAna.py /txt文件路径这里的输入都可以通过拖动来完成,如下面动图: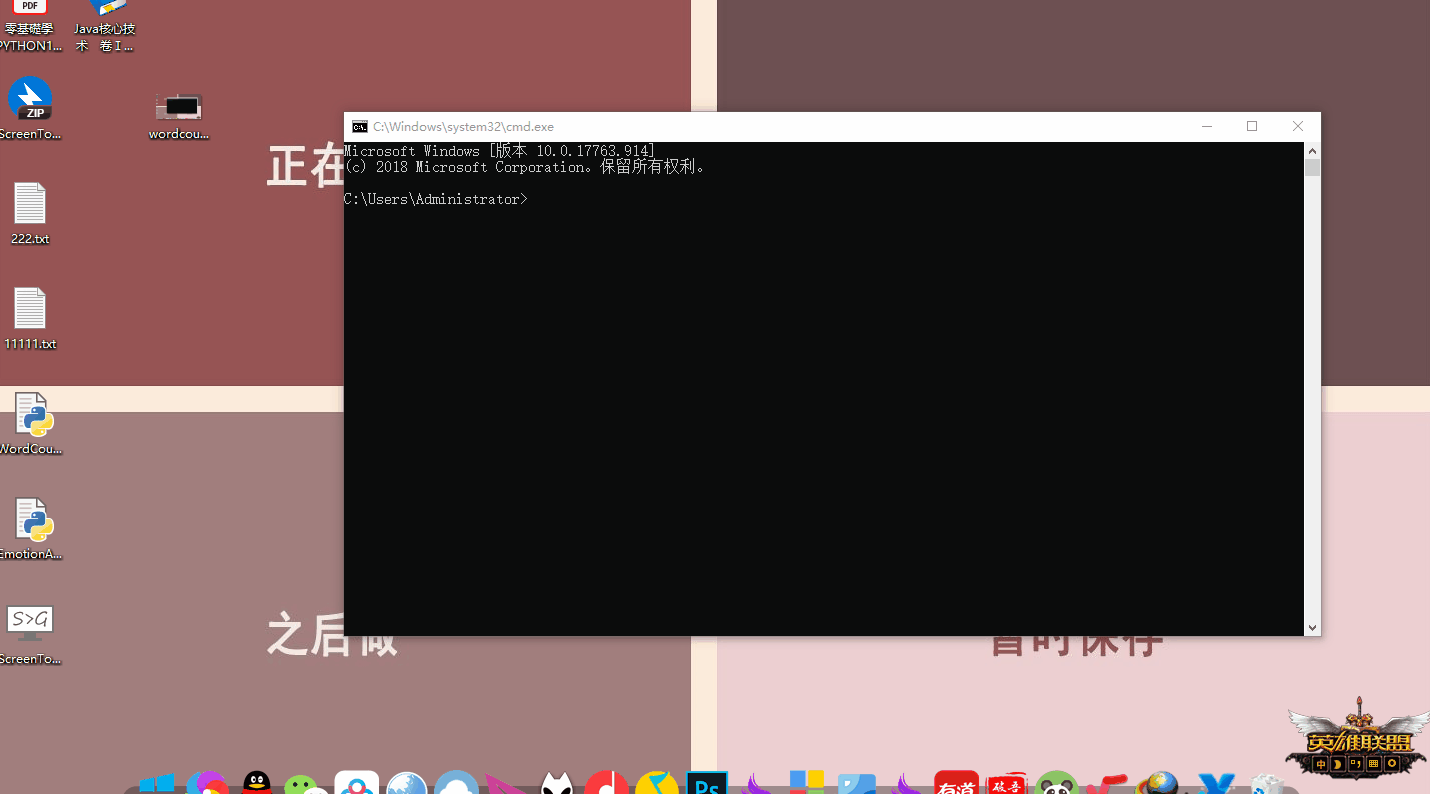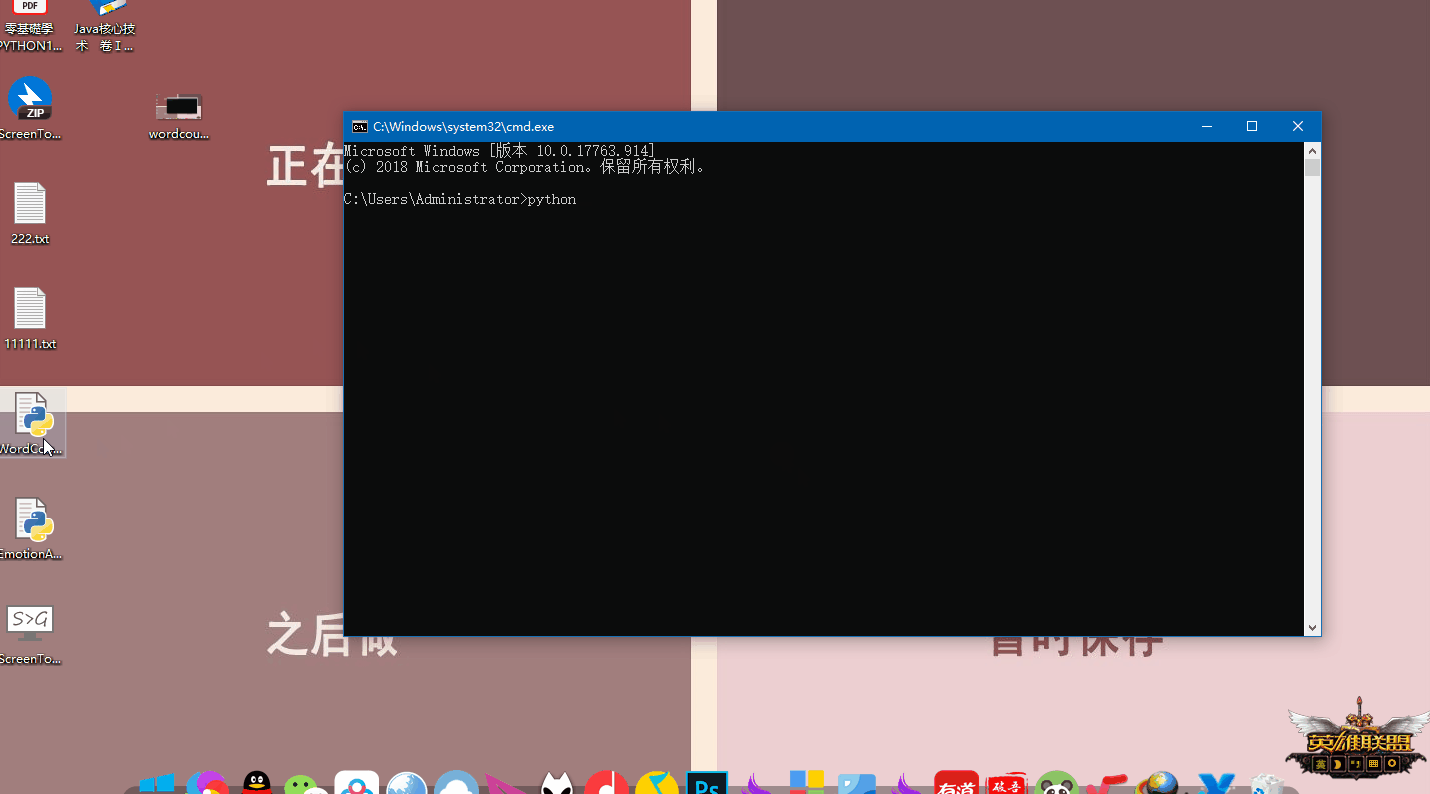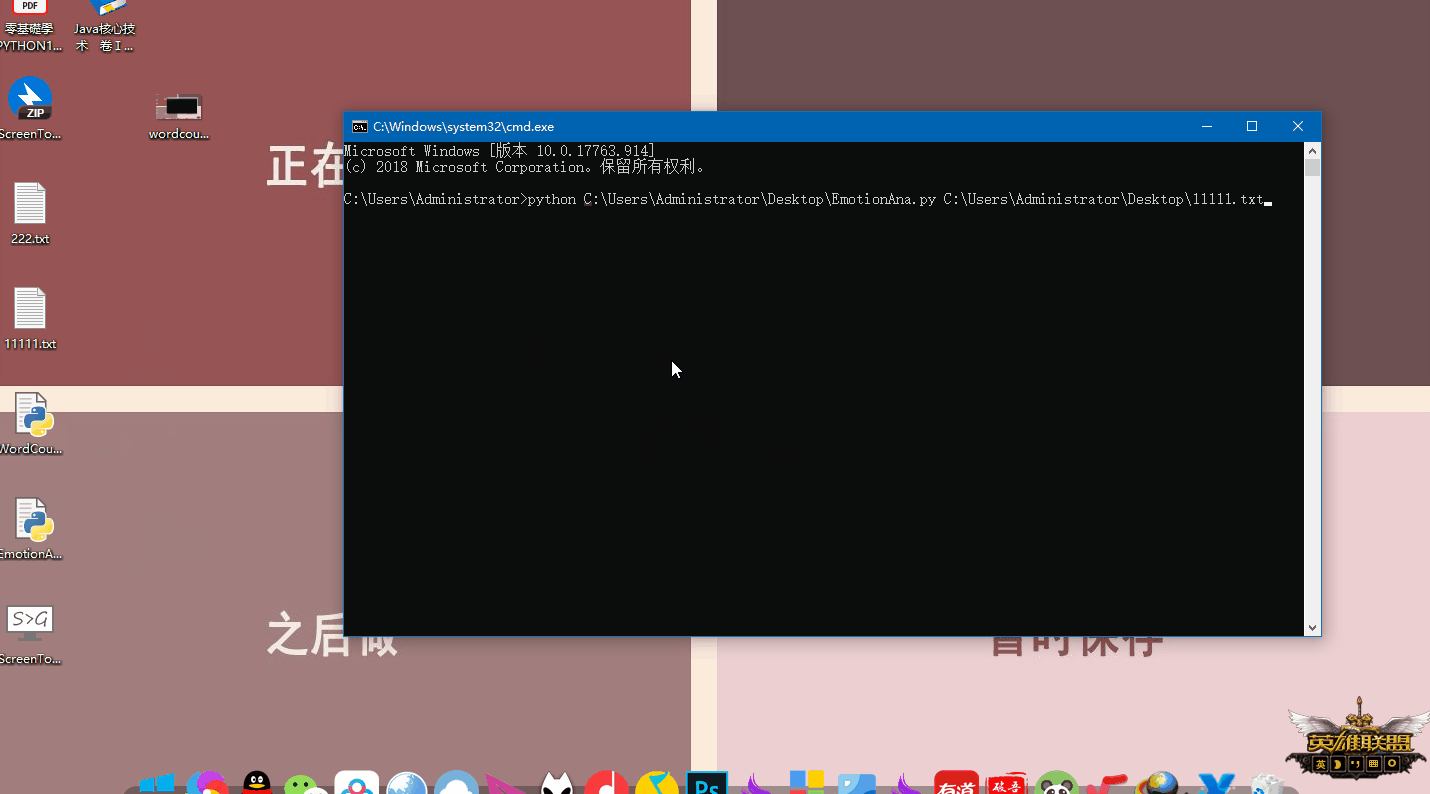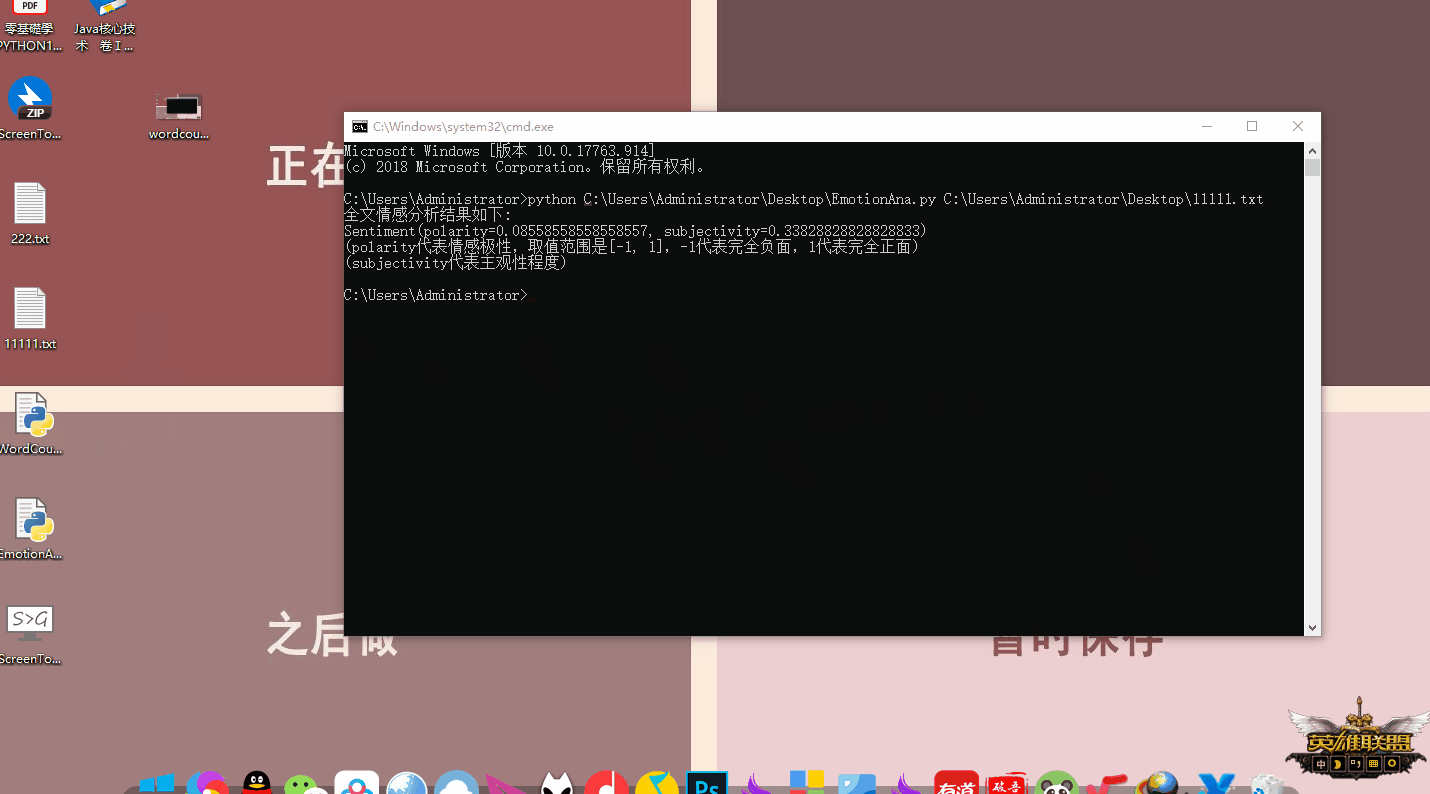
注意每次拖动前都要先加一个空格,不能让路径连在一起。